
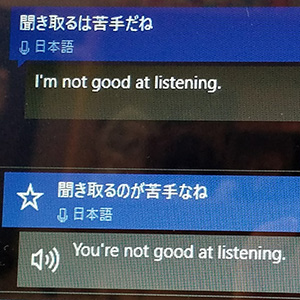
MSトランスレーターのパソコンの画面。「聞き取るのは苦手だね」と話したら、日本語の「の」が抜けていたり、「だね」が「なね」になっていたり
自動音声翻訳ソフト「マイクロソフト・トランスレーター(MST)」がすごい、というので、試してみた。日本語の英訳で使ってみた感想は――日本語はまだまだ発展途上、現状では幼稚園児から小学生レベルという感じだ。聞き取りも語彙も、英語に比べて圧倒的に日本語が苦手なのが分かる。辞典がすでに充実している英語と違って、日本語はまだ学習中だから当然かもしれない。日本語使いが世界中で話しかければかけるほど、クラウドに集まる用例データが充実し、AI(人工知能)は賢くなる。将来的には、よりちゃんと聞き取れ、微妙なニュアンスまで訳せるようになるはず、と期待したい。
MSTの仕組みはこうだ。コルタナ(音声認識ソフト)の技術が、発話者の会話を聞き取って、データをテキスト変換して、携帯やパソコン上に文字で表示してくれる。そのテキストを、MSTが、使い手が指定した言語に翻訳して表示し、さらにその文章をネイティブに似た発音とイントネーションで読み上げる。聞き取ってテキストにするまでがコルタナ、テキストを翻訳して音声発信するところがトランスレーターの役割と、二段構えになっている。音声やテキストのデータはクラウド上に集められ、用例や語彙をAIが学習することで、どんどん賢くなるという。MSTは無料枠があるため、個人が私用で使う程度ならば課金はされない。
携帯(アンドロイド)にMSTをダウンロードし、MSの音声認識ソフト「コルタナ」に日本語で話しかけ、英訳させてみた。
実際に使ってみて、以下の六つのことを感じた。
1)日本語は英語に比べてずっと下手。特に聞き取りが苦手。
私のしゃべり方が速いせいかもしれないが、携帯のコルタナに話しかけても、最初はほとんど正しく聞き取ってくれなかった。
正しい日本語に変換されないと、正しく訳せない。最初の壁が母国語だったとは。
また、日本語のテキストを読み上げさせた時の発音も今一つ。自動読み上げシステムの、あの、ごつごつした感じが耳障りだ。微妙にイントネーションが違う部分も。日本語は本当にまだまだ学習中、ということなのね。
2)特に聞き取れないのが、日本語の接尾語だ。
会話の語尾につける念押しの接尾語「ね」を、「ないい」「な。いい」などと聞いてしまう。
例えば、「『ね』は聞き取れないね」と話しかける。携帯に表示された日本語の文章は、「ねいば付きトレーナーね」。はあ?? もう一度、同じことを言う。次は、「ねいは聞き取れぬ、いい」。「ね」という接尾語自体が語彙にないのか?
特に「ね」が苦手なようだ。「かい」は聞き取れた。「君は人格があるかい。」は正しく聞き取って表示し、「Do you have a personality?」と訳した。
ただし、ソフトは少しずつ学習しているのかもしれない。「~ね」の文章をしゃべった後、「ないい」になっていたテキストの文末を、文字入力で「ね」と直してやってから、何回か立て続けに「~ね」を付けたセリフをしゃべって聞かせたところ、その連続した数回は「~ね」と正しく聞き取った。残念なことに、しばらく間をおいて再び「~ね」の用例をしゃべったら、また「ないい」に戻ってしまったが。
バカだな、まだこいつ。記憶できない。というわけで、3歳児並みと認定(3歳児に失礼かも?)。
(この項、2に続く)
(2017・8・3、元沢賀南子執筆)

